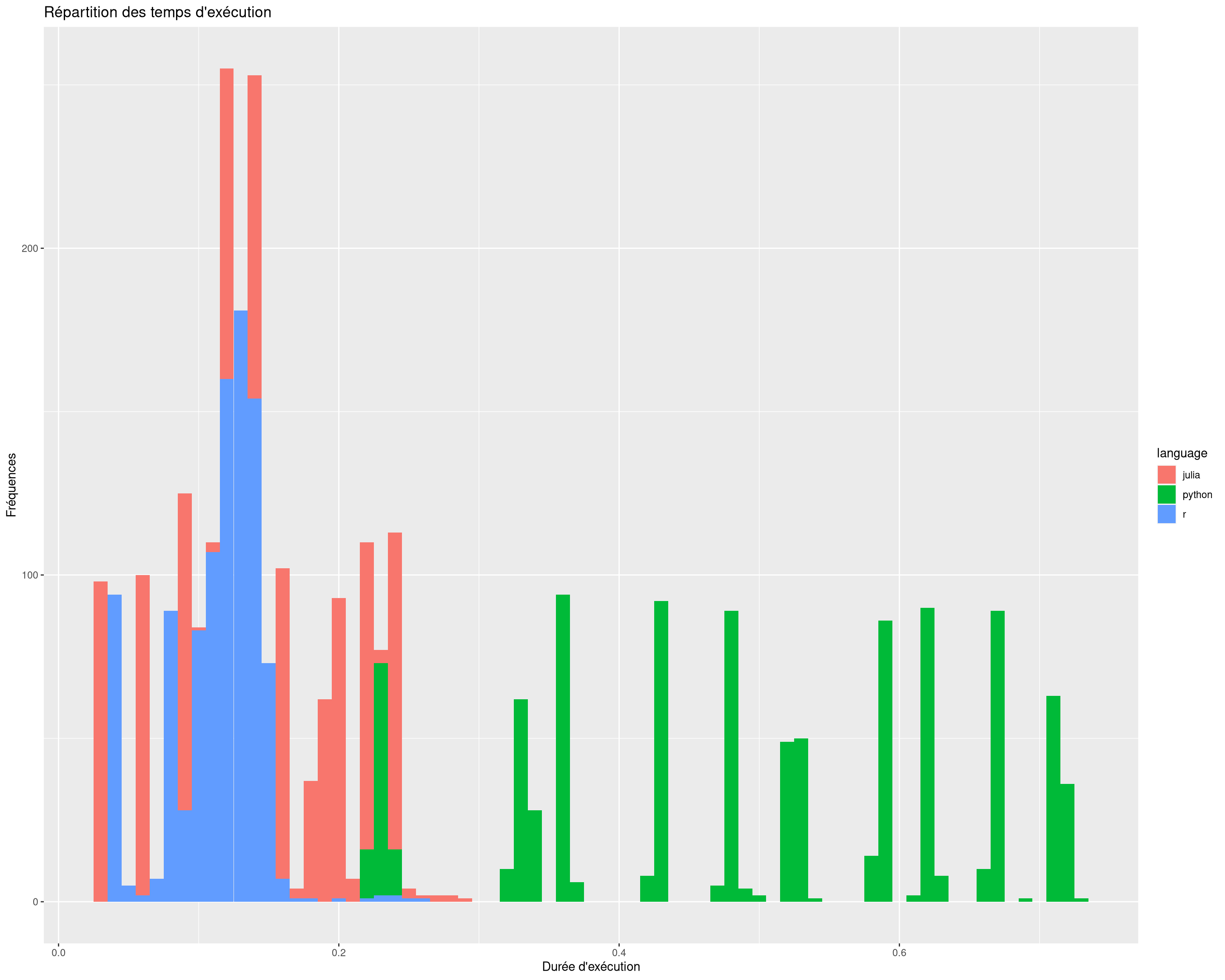
temp0 |>mutate(dur = t1 - t0 ) |>filter(dur <=5) |>ggplot() +geom_histogram(aes(dur,fill = language), binwidth =0.01) +ggtitle("Répartition des temps d'exécution")+labs(x ="Durée d'exécution", y ="Fréquences")
On voit bien les vagues correspondants aux différentes tailles de dataset en python. Le julia et le R restent assez concentré. Même si julia tend a être plus dispersé.
Répartition par language
Code
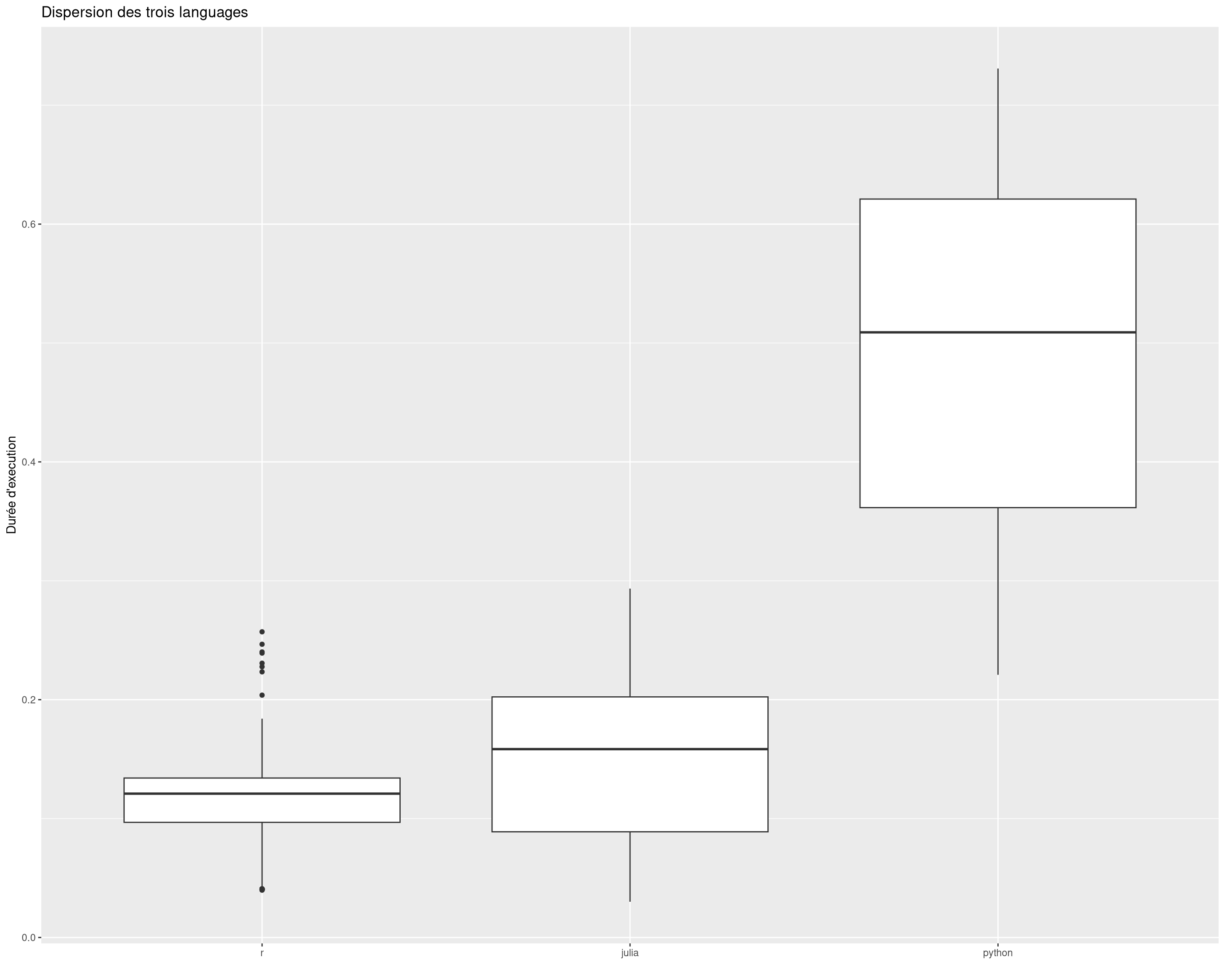
temp0$taille_dataset =as.factor(temp0$taille_dataset)temp0$language =as.factor(temp0$language)temp0 |>mutate(dur = t1 - t0 ) |>filter(dur <=5) |>arrange(dur)|>#fct_reorder(bean_continent,rating,.fun="median")ggplot(mapping =aes(x =fct_reorder(language,dur,.fun="median"), y = dur))+geom_boxplot()+ggtitle("Dispersion des trois languages")+labs(x ="", y ="Durée d'execution")
On voit au global que l’exécution de R est très peu dispersées. On a fait tourner 100 analyses sur des tailles de bases de données de 100 200 … 1000. La différence avec python est indéniable.
Ici on peut voir que pour l’execution de cette tâche, Julia est plus lent que R. C’est plutot surprenant. On pourrait soit s’attendre à ce que Julia soit plus rapide. Mais cette tâche étant essentielement d’appeller des fonction C++, les deux languages devraient être au pire équivalents. Il se peut qu’il y ai eu des erreurs lors du design du benchmark.
Evolution en fonction de la taille des données
Code
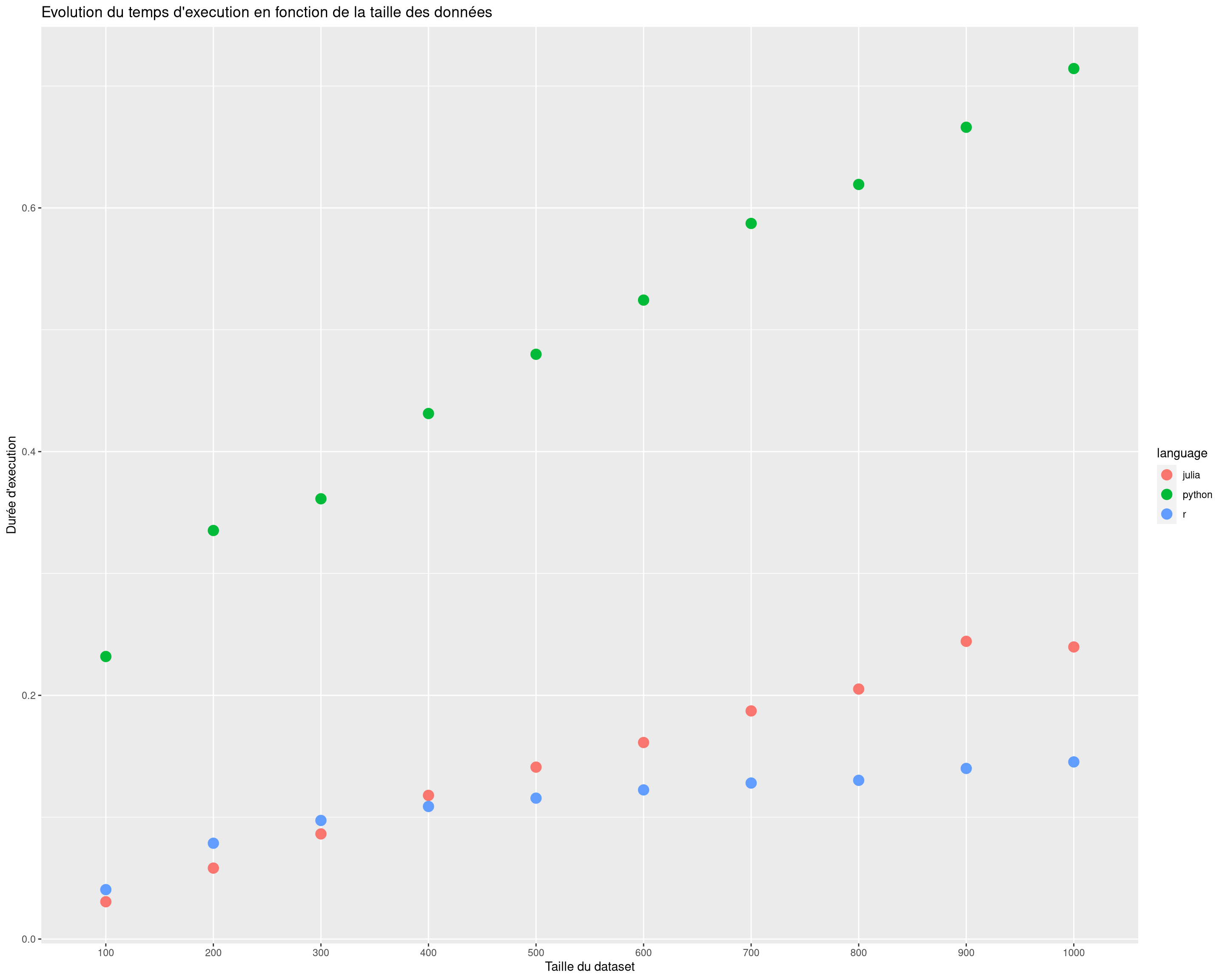
temp0 |>group_by(taille_dataset, language) |>summarize(t0 =median(t0),t1 =median(t1) )|>mutate(dur = t1 - t0 ) |>filter(dur <=5) |>ggplot(aes(taille_dataset, dur))+geom_point(aes(color = language), size =4)+ggtitle("Evolution du temps d'execution en fonction de la taille des données")+labs(x ="Taille du dataset", y ="Durée d'execution")
`summarise()` has grouped output by 'taille_dataset'. You can override using
the `.groups` argument.
Pour revenir au commentaire d’introduction, on peut voir que julia est plus rapide que R sur les petits datasets et se fait battre pour des datasets avec plus de 300 lignes. De plus on dirait que la croissance de la durée d’exécution de R est logarithmique alors que celle de julia semble linéaire.
Bilan
On voit que R reste plus rapide que Julia. Après lecture du manuel de performance de julia, on peut voir que le code julia pouvait être optimisé. C’est pour cela qu’il est est sous la forme du fonction au lieu d’un for dans le programme global. Mais les performances sont restées identiques.
Ensuite par rapport à la compilation,packager le module et utiliser des contraintes de types sur les arguments des fonctions et des itérateurs dans les boucles pourraient aider.
On peut voir que le code Julia demande des connaisances avancées sur le languages et le fonctionnement de la compilation pour être emmené à son plein potentiel.
Source Code
---title: "Performances"format: html: code-fold: true---```{r}#| output: falselibrary(tidyverse)temp0 =read.csv("../../04_benchmark_xgboost/r_duration.csv")temp0 =rbind(temp0, read.csv("../../04_benchmark_xgboost/julia_duration.csv"))test_python =read.csv("../../04_benchmark_xgboost/python_duration.csv")temp1 = test_python |>select(language, t0,t1,taille_dataset)temp0 =rbind(temp0, temp1)```## Histogramme brut```{r}#| fig.height: 12temp0 |>mutate(dur = t1 - t0 ) |>filter(dur <=5) |>ggplot() +geom_histogram(aes(dur,fill = language), binwidth =0.01) +ggtitle("Répartition des temps d'exécution")+labs(x ="Durée d'exécution", y ="Fréquences")```On voit bien les vagues correspondants aux différentes tailles de dataset en python. Le julia et le R restent assez concentré. Même si julia tend a être plus dispersé. ## Répartition par language```{r}#| fig.height: 12temp0$taille_dataset =as.factor(temp0$taille_dataset)temp0$language =as.factor(temp0$language)temp0 |>mutate(dur = t1 - t0 ) |>filter(dur <=5) |>arrange(dur)|>#fct_reorder(bean_continent,rating,.fun="median")ggplot(mapping =aes(x =fct_reorder(language,dur,.fun="median"), y = dur))+geom_boxplot()+ggtitle("Dispersion des trois languages")+labs(x ="", y ="Durée d'execution")```On voit au global que l'exécution de R est très peu dispersées. On a fait tourner 100 analyses sur des tailles de bases de données de 100 200 ... 1000. La différence avec python est indéniable. Ici on peut voir que pour l'execution de cette tâche, Julia est plus lent que R. C'est plutot surprenant. On pourrait soit s'attendre à ce que Julia soit plus rapide. Mais cette tâche étant essentielement d'appeller des fonction C++, les deux languages devraient être au pire équivalents.Il se peut qu'il y ai eu des erreurs lors du design du benchmark. ## Evolution en fonction de la taille des données```{r}#| fig.height: 12temp0 |>group_by(taille_dataset, language) |>summarize(t0 =median(t0),t1 =median(t1) )|>mutate(dur = t1 - t0 ) |>filter(dur <=5) |>ggplot(aes(taille_dataset, dur))+geom_point(aes(color = language), size =4)+ggtitle("Evolution du temps d'execution en fonction de la taille des données")+labs(x ="Taille du dataset", y ="Durée d'execution")```Pour revenir au commentaire d'introduction, on peut voir que julia est plus rapide que R sur les petits datasets et se fait battre pour des datasets avec plus de 300 lignes. De plus on dirait que la croissance de la durée d'exécution de R est logarithmique alors que celle de julia semble linéaire. ## BilanOn voit que R reste plus rapide que Julia. Après lecture du [manuel](https://docs.julialang.org/en/v1/manual/performance-tips/) de performance de julia, on peut voir que le code julia pouvait être optimisé. C'est pour cela qu'il est est sous la forme du fonction au lieu d'un for dans le programmeglobal. Mais les performances sont restées identiques. Ensuite par rapport à la compilation,packager le module et utiliser des contraintes de types sur les arguments des fonctions et des itérateursdans les boucles pourraient aider. On peut voir que le code Julia demande des connaisances avancées sur le languages et le fonctionnement de la compilation pour être emmené à son plein potentiel.